NVHopper
NVIDIA Hopper 架构GPU浅析
0. 引言
2022年GTC大会,老黄介绍了基于NVIDIA最新Hopper架构的NVIDIA H100 Tensor Core GPU。本文将带你深入Hopper架构并介绍Hopper架构的一些重要新特性。
1. NVIDIA H100 Tensor Core GPU简介
NVIDIA H100 Tensor Core GPU是NVIDIA发行的第九代数据中心GPU,该GPU被设计用来在大规模人工智能应用以及高性能计算应用中提供相较于前代商品NVIDIA A100 Tensor Core GPU数量级级别的提升。H100继承了A100上为提升人工智能及高性能计算性能的设计特点,且显著提高了架构效率。图1展示了基于新SXM5板卡的NVIDIA H100 Tensor Core GPU。

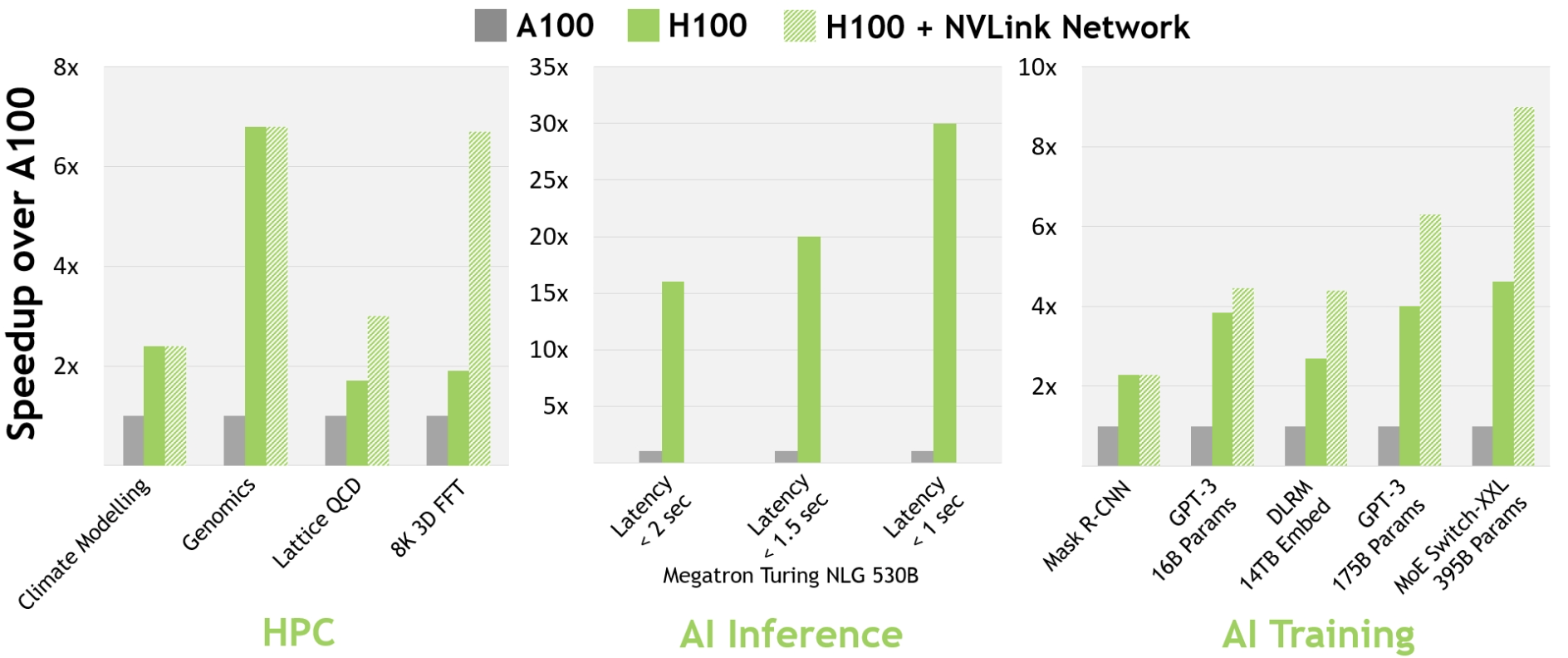
对于如今主流的人工智能以及高性能计算任务,配备有InfiniBand互联技术的H100相比A100能提供最多30倍的性能提升(译者:可能类似AMD Infinity Fabric,致力于提升设备、节点间的带宽)。最新的NVLink互联系统主要着眼于如今最具挑战性的、需要大量GPU计算节点提供加速进行模型并行的任务。基于InifniBand的加持,这些任务在H100上的性能又一次得到了飞跃。图2展示了A100, H100, H100+InfiniBand在高性能计算、AI训练与推理任务中的性能。
在本次GTC上,NVIDIA发布了新的NVIDIA Grace Hopper Superchip产品。 NVIDIA Hopper H100 Tensor Core GPU将为NVIDIA Grace Hopper Superchip CPU+GPU架构提供动力,该架构专为TB级加速计算而打造,并能在大型人工智能模型以及高性能计算任务重提供超10倍的性能。NVIDIA Grace Hopper Superchip利用Arm架构的灵活性从头开始设计用于加速计算de CPU和服务器架构。 H100与NVIDIA Grace CPU通过NVIDIA的芯片互联技术连接,提供900 GB/s的总带宽,比PCIe Gen5快7倍。 与当今最快的服务器相比,这种创新设计可提供高达30倍的总带宽,并为使用巨量数据的应用提供超10倍的性能提升。
下面是NVIDIA H100 Tensor Core GPU新特性的简要总结:
- 新设计的流多处理器(SM)提供了许多性能及效率上的提升,具体如下:
- 第四代张量核心:若将每个SM的提升、SM数量的提升以及频率的提升结合考虑,
H100相比A100能提供超6倍的性能提升。在每个SM层面,H100相比A100在每种数据类型上能提供2倍的矩阵乘加(MMA)性能,在FP8数据类型上,相比于FP16数据类型则能提供4倍于A100的性能。而张量核心的稀疏特性能够利用深度学习中的细粒度结构化稀疏,提供2倍于稠密张量计算的性能。 - 新的
DPX指令:该指令能够加速动态规划算法,相比A100提升7倍的性能。例如基因组处理中的Smith-Waterman算法以及为机器人队伍寻找最优路径的Floyd-Warshall算法。 - 3倍性能的IEEE标准浮点处理性能:相比
A100,SM同频浮点性能为2倍。而得益于更高的频率以及更多的SM,总体性能为3倍。 - 新的抽象层
Thread block Cluster:这一特性能够使程序员能够显式地以大于运行在一个SM上的一个线程块Thread block的粒度控制程序的局部性。这一特性通过增加一个抽象层扩展了CUDA编程模型,现在的编程模型包括thread,thread block,thread block cluster,grid。Thread block cluster能够使多个线程块同时运行于多个SM,并支持同步、集合通信以及数据交换。 - 分布式共享内存:这一机制允许SM之间点对点横跨多个SM的共享内存地进行包含
load,store以及源自操作在内的通信。 - 新的异步执行模型:通过张量存储加速器
TMA能够在全剧内存以及共享内存间进行更高效的大规模数据通信。TMA同样还支持thread block cluster内的thread block进行异步数据拷贝。为保证数据原子移动以及同步,TMA还加入了新的异步事物屏障(asynchronous transaction barrier)。
- 第四代张量核心:若将每个SM的提升、SM数量的提升以及频率的提升结合考虑,
- 新的Transformer引擎:该引擎结合张量核心以及软件特性专门加速Transformer模型的训练与推理。该引擎能够智能地管理计算过程,动态地在FP8以及FP16精度之间选择,自动处理层之间不同数据精度地重用和缩放。在大型语言模型上相比
A100能获得9倍训练性能和30倍推理性能地提升。 HBM3显存子系统:相比前代产品这一系统能提供将近2倍地带宽。H100 SXM5 GPU是世界上第一款配备了HBM3显存并提供领先的3 TB/s显存带宽地GPU。50MB的L2缓存:缓存更多的数据、模型,以减少访存HBM3。- 第二代多实例GPU技术(
Multi-Instance GPU):相比A100,每个GPU实例能提供3倍的计算能力以及2倍的访存带宽。且本代产品开始每个GPU实例能够提供加密保密计算。H100最多能够提供7个GPU实例,每个实例都有各自的图像视频解码单元(NVDEC,NVJPG)。现在每个GPU实例都有独立的性能监视器。 - 新的隐私计算支持:新机制能够保证在虚拟机或GPU实例中的用户数据具有更高的安全性,防止硬件、软件的攻击,更好地隔离资源。
H100实现了世界上第一个原生的GPU配合CPU的加密计算以及高可信运行环境,并且完全匹配PCIe标准。 - 第四代
NVLink:相比前代产品,H100在All-Reduce运算中能够提供3倍的带宽,而各种应用平均能提升50%的带宽。NVLink能提供7倍于PCIe Gen5的带宽(900 GB/s)。 - 第三代
NVSwitch:这一技术同时包含节点内部以及节点外部用于互联在服务器、集群及数据中心中多个GPU的网络。节点内部每个NVSwitch提供64个NVLink端口以加速多GPU互联速率。相比前代产品,整个互联网络的吞吐量从7.2 Tbits/s提升到13.6 Tbits/s。新一代互联网络同时在硬件上加速了包含多播、归约等集合通信。 - 新的硬件互联系统:基于
NVLink以及NVSwitch技术,新的互联系统支持32个节点或256个GPU以2:1胖树拓扑相连接。这一连接方式能够提供57.6 TB/s的互联带宽从而达到在FP8精度下1 exaFLOP的稀疏计算性能。 PCIe Gen5:相比Gen4,能够提供双向共128 GB/s的带宽。PCIe Gen5使得H100能够以最高的性能与x86 CPU,SmartNICs以及DPU连接
除上文提到的信特性外,还有许多新细节能够提升性能、减小延迟和开销、提升编程便利性。