本文主要介绍了一种用于GPU设计过程中设计空间探索(Design Space Explore,DSE)的系统,通过将设计参数与GPU Kernel的运行性能数据输入给一个可解释的机器学习模型(有点类似随机森林的决策树算法)来衡量不同任务下不同设计参数的优劣。当然这篇文章最重要的贡献我认为不在于模型准确率活着加速GPU架构设计等等,而在于其挖掘的GPU设计参数对于计算任务的影响,以及参数之间互相影响的模式。
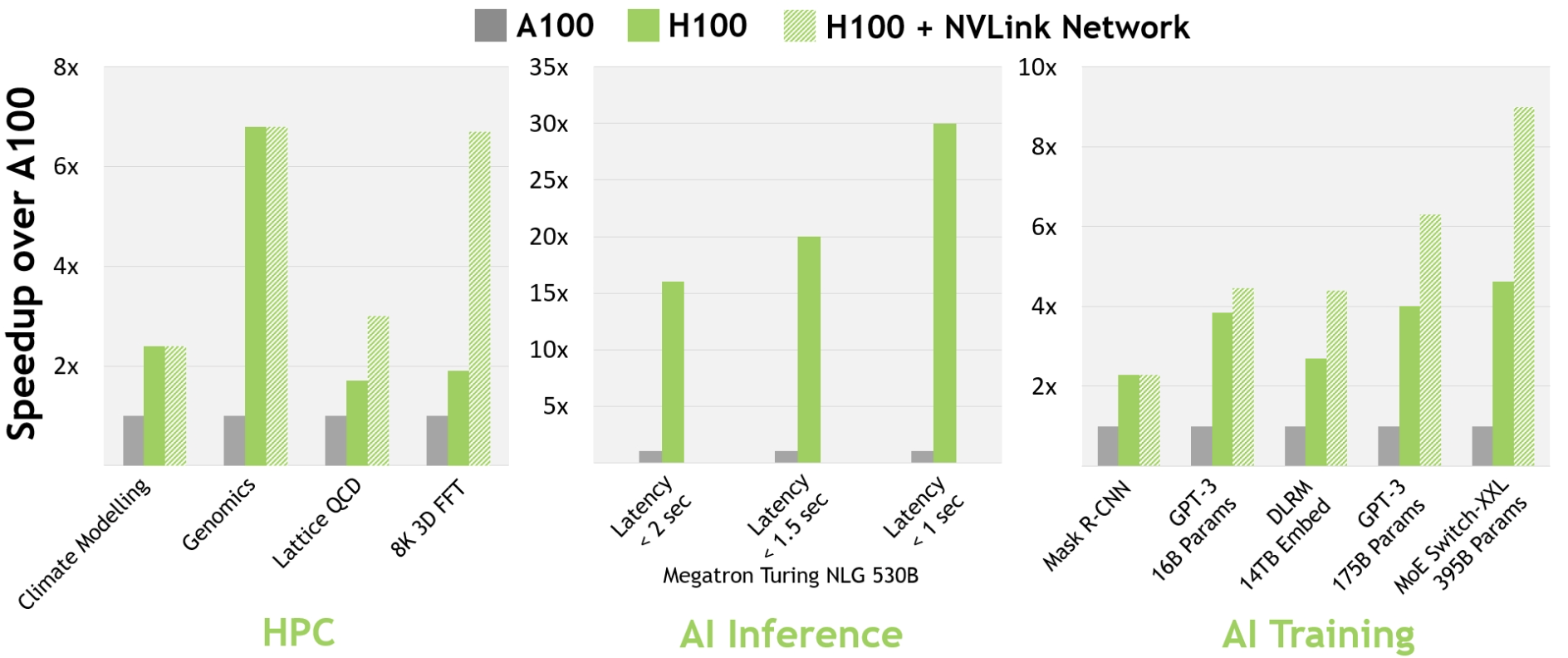
This work proposed an explainable performance model of GPGPUs, based on which the authors first predict the performance of a given kernel on giver hardware with high accuracy, then explain the relation between GPGPU behaviors and design parameters.
2. Strength
The paper is well organized and well-motivated.
The performance model they use is highly explainable with considerable accuracy.
Some important design insights are revealed via their model.
The performance model can be easily generalized to other hardware and other performance metrics (from IPS to Power consumption).
3. Weakness
Some findings are misleading, which will be datailed in questions and comments.
4. Questions and Comments to Authors
The problem this work target is emerging and important, and the authors explain their motivation well.
In the analysis of importance analysis, the core frequency is treated as the most important design factor. While this parameter is not the most challenging factor the hardware designers concerned. It’s trival that with higher frequency the performance and power of a GPGPU kernel will increase. So is the instruction replay overhead which is a factor related to the profiler itself. I think it’s necessary to filter out the influence of these parameters other wise some misleading findings will be given. (For example, execute all the kernels at a fixed core frequency or fixed power budget)
I think the benchmark amount and the problem size are limited, and the register per thread is always sufficient. While for some recent applications with very heavy computation burdens, there may exist other patterns. (这点其实有点时空警察,但是2018年应该也是有那些很大的模型、很大的计算任务了)
GPUWattch is available for power estimated with higher explainable.
Overall, the findings and hardware patterns proposed in this work is reasonable and insightful.
It’s universally acknowledged that deep learning applications are evolving fast and are becoming more and more complex. For example, In cloud service and auto-piloting, we need to provide service to several deep learning models. However, currently, the computation power of hardware also increases significantly, for example, Threadripper 3990X CPU has ~15 TFLOPS for FP32 while Radeon Instinct MI100 has>100 TFLOPS for matrix computation. This situation resulted in a problem that the performance of single hardware is far beyond the requirement of a single inference task of model: the QoS requirement of ResNet-50 in MLPerf is 15ms while the whole CPU use only 6ms to finish the job. Under this circumstance, we need multi-tenant. In another word, we need to co-locate multiple tasks, or queries, onto one hardware.
Current Solutions
We can divide current solutions into hardware and software solutions. The hardware solutions mainly bypass the complex resource management of co-locating tasks by temporal sharing or physical isolation, like AI-MT for temporal sharing and NVIDIA MIG for resource isolation. For software solutions, there are some task co-locating solutions for traditional workloads including Parties, for deep learning tasks, DART proposed a cluster scale scheduling strategy. While our work mainly focuses on CPU scale strategy.
A straightforward solution
Of course, we have some simple, straightforward solutions. On CPUs, we can use MPI to serve multiple tasks and use CPU affinity and tools including res control, Intel CAT to limit resource usage. On GPUs, we have Multi-Process Service, Persistent Thread Block. These techniques support simply dumping multiple tasks onto single hardware. But how about the performance? It’s not good. Following list is an example of doing so.
The first is co-locating interference, according to our verification experiment, co-locating 4 identical GoogLeNet tasks on a CPU platform have 1.8x latency. If we inspect the system performance counter including LLC miss rate, LLC access, we observe server shared resources contention.
The second is low QoS satisfaction rate. With the increase of QPS (Query Per Second), the satisfaction rate of the system drop significantly. Even if we apply fine-grained scheduling (schedule every layer/op of the network seperatly), the system with AMD Threadripper 3990X can only serve 50 queries with 99% satisfaction rate, while the theoritical performance of the CPU is far beyond this.